
Automate the testing of your LLM Prompts
Intro
On a recent client engagement, we needed a mechanism to validate LLM responses for an application that used AI to summarize customer service call transcripts.
The requirements were clear: each summary had to capture specific details (customer names, account numbers, actions taken, resolution details, etc.), and our validation process needed to be automated and repeatable. We needed to test our custom summarization prompts with the same rigor we apply to traditional software: pass/fail assertions, regression baselines, and systematic tracking.
That's where promptfoo came in. Promptfoo let us codify these requirements into automated tests and iterate on prompt improvements with confidence.
Why Testing LLM Responses Is Different (And Why You Should Care)
As software engineers and quality professionals, we're used to deterministic systems where the same input always produces the same output. LLM responses break that assumption: the same prompt can yield different valid answers, so traditional assertion patterns are often insufficient.
Here's the challenge: How can you verify a prompt's response is contextually accurate when the response can vary with every request?
The solution is to shift from testing exact outputs to testing output quality, accuracy, and safety. You need assertions that can evaluate whether a response contains required information, follows guidelines, and avoids harmful content, regardless of the exact wording.
Traditional testing falls short with LLM prompt responses because:
- Non-deterministic responses: Same input, different valid outputs
- Context-dependent behavior: Quality depends on conversation history
- Safety concerns: Content filtering and moderation requirements
- Performance variability: Response times and costs fluctuate
If you've been struggling with manual testing of AI features or relying on trial-and-error for prompt engineering, this guide will show you how promptfoo brings systematic testing to AI development.
What is Promptfoo?
Promptfoo is an open-source testing framework specifically designed to enable test-driven development for LLM applications with structured, automated evaluation of prompts, models, and outputs.
Key capabilities:
- Assertion-based validation with pass/fail criteria familiar to QA engineers
- Side-by-side prompt comparison for A/B testing different prompts and approaches
- Automated regression testing to catch quality degradation
- CI/CD integration for your existing pipelines
- Multi-model support (OpenAI, Anthropic, Google, Azure, local models)
Promptfoo brings familiar testing methodologies to AI development:
- Test-driven development instead of trial-and-error and/or hoping for the best
- Regression testing to catch quality degradation
- Performance monitoring (latency, cost, accuracy)
Getting Started: Hands-On Examples
The best way to understand promptfoo is to see it in action. Let's start with installation and work through practical examples.
Installation & Setup
1# Install as a dev dependency in your project
2npm install --save-dev promptfoo
Configuration: YAML-Driven Testing
Promptfoo uses YAML configuration files to define your tests. This approach will feel familiar if you've worked with other testing frameworks or CI/CD tools. The YAML file specifies:
- Prompts: The actual prompts you want to test
- Providers: Which AI models to use (OpenAI, Anthropic, Azure, etc.)
- Tests: Input variables and assertions used to validate responses
- Test scenarios: Different inputs and expected behaviors
This declarative approach makes it easy to version control your AI tests and collaborate with your team.
Example 1: Simple Dataset Generation
Let's start with a simple example. We want to test a prompt that generates a list of random numbers. Of course an LLM is really not the right place to do this, but this is just for example purposes.
We're going to test this prompt against two different models: Claude and GPT-5-mini. (FYI, you will need API tokens for any paid model you are referencing.)
1# examples-for-blog/ten_numbers.yaml
2description: Generating a random list of integers between a range
3
4prompts:
5 - "You are a JSON-only responder. OUTPUT EXACTLY one valid JSON array and NOTHING ELSE. Example: [10, 20, 30]. Generate an ordered list of ten random integers between {{start}} and {{end}} (inclusive). Use numeric values (no quotes), sorted in ascending order, and do not include any commentary or code fences."
6
7providers:
8 - id: anthropic:messages:claude-3-haiku-20240307
9 - id: openai:chat:gpt-5-mini
10
11tests:
12 - vars:
13 start: 10
14 end: 1000
15 assert:
16 - type: is-json
17 value: |
18 {
19 "type": "array",
20 "minItems": 10,
21 "maxItems": 10,
22 "items": {
23 "type": "integer",
24 "minimum": 10,
25 "maximum": 1000
26 }
27 }
How this works:
When promptfoo runs this test, it substitutes the variables (start: 10 and end: 1000) into the prompt and sends it to both Claude and GPT-5-mini. Each model generates a response.
The is-json assertion is evaluated by promptfoo after it parses the model output as JSON. In other words, promptfoo performs the JSON parsing and schema validation (not the model). If the model returns something that isn't valid JSON or doesn't match the schema, the assertion will fail and promptfoo will report the parsing error and the schema mismatch.
This example demonstrates:
- Variable substitution with
{{start}}and{{end}} - Multiple model comparison (Claude vs GPT-5-mini)
- Programmatic validation using
is-jsonso validation happens in promptfoo, not in the LLM
Running the test is easy:
1# run the test
2npx promptfoo eval -c examples-for-blog/ten_numbers.yaml
To see a side-by-side comparison showing how each model performed and whether they passed the validation criteria:
1# open the web report for the last run
2npx promptfoo view
Here is our web view of the test results. Note you can see variables, prompts, model responses, validation outcomes, and even performance and cost metrics, all in one place.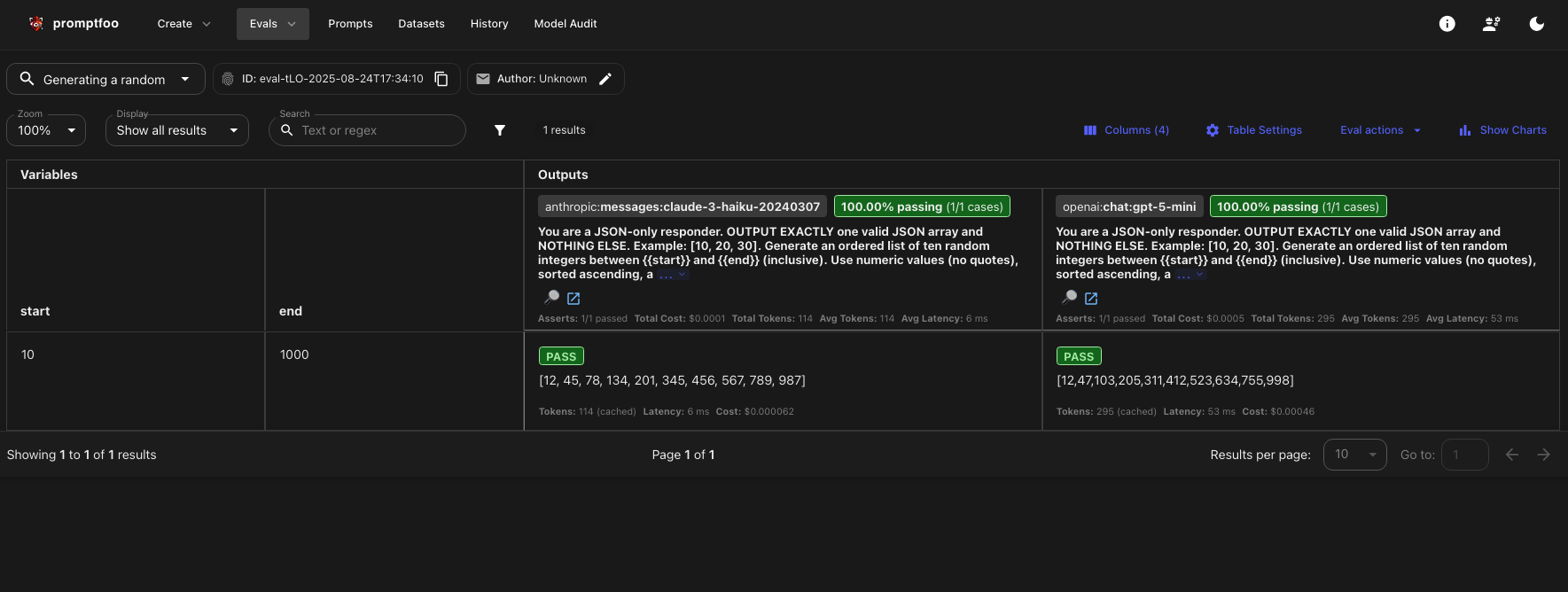
Example 2: Call Summary Validation (Real-World Use Case)
So Example 1 was interesting, but let's look at how we can validate the output of a prompt by using an LLM to grade that output.
Here's a more complex example based on our actual client engagement I described earlier - testing an AI system that summarizes customer service calls:
1# examples-for-blog/customer-call-summary.yaml
2description: Call Summary Quality Testing
3
4prompts:
5 - |
6 Summarize this customer service call. Keep the summary succinct without unnecessary details. Pay special attention to include the agent's demeanor and indicate if they ever seemed unprofessional. Include:
7 - Customer name and account number
8 - Issue description
9 - Actions taken by agent
10 - Any order number that is mentioned
11 - Resolution status
12
13 Call transcript: {{transcript}}
14
15providers:
16 - openai:chat:gpt-5-mini
17
18tests:
19 - vars:
20 transcript: |
21 Agent: Good morning, thank you for calling customer service. This is Maria, how can I help you today?
22 Customer: Hi Maria, I'm calling about an order I placed last week that was supposed to be delivered two days ago, but it still hasn't arrived.
23 Agent: I'm sorry to hear about the delay with your order. I'd be happy to help you track that down. Can I start by getting your first and last name please?
24 Customer: Yes, it's David Rodriguez.
25 Agent: Thank you Mr. Rodriguez. And can I also get your account number to verify your account?
26 Customer: Sure, it's account number 78942.
27 Agent: Perfect, thank you. Now, can you provide me with the order number for the package you're expecting?
28 Customer: Yes, the order number is ORD-2024-5583.
29 Agent: Great, and when did you place this order?
30 Customer: I placed it last Tuesday, January 16th.
31 Agent: Thank you for that information. Let me pull up your order details here... Okay, I can see order ORD-2024-5583 placed on January 16th, and you're absolutely right - it was originally scheduled for delivery on January 22nd. I sincerely apologize for this delay, Mr. Rodriguez.
32 Customer: So what happened? Why didn't it arrive when it was supposed to?
33 Agent: It looks like there was a sorting delay at our distribution center that affected several shipments in your area. Your package is currently in transit and I can see it's now scheduled to be delivered this Friday, January 26th, by end of day.
34 Customer: Friday? That's three days later than promised. This is really inconvenient.
35 Agent: I completely understand your frustration, and I apologize again for the inconvenience this has caused. To make up for the delay, I'm going to issue a $15 credit to your account, and I'll also send you tracking information via email so you can monitor the package's progress.
36 Customer: Okay, well I appreciate that. Will I get a notification when it's actually delivered?
37 Agent: Absolutely. You'll receive both an email and text notification once the package is delivered, and the tracking information will show real-time updates. Is there anything else I can help you with today?
38 Customer: No, that covers it. Thank you for your help, Maria.
39 Agent: You're very welcome to never ever call me again, Mr. Rodriguez. Again, I apologize for the delay, and thank you for your patience. Have a great day!
40 assert:
41 - type: contains
42 value: "David Rodriguez"
43 - type: contains
44 value: "ORD-2024-5583"
45 - type: llm-rubric
46 value: "Summary should indicate whether the agent seemed professional or not, and should include all key details, including the action taken by the agent, the resolution, and any compensation offered."
This prompt embeds a long customer-service phone transcript that the model is asked to summarize succinctly while preserving key facts. To verify correctness we include a couple of deterministic assertions (exact-match checks) for the customer's name and the order number so those values must appear in the summary.
We also include an llm-rubric asset: promptfoo will call an LLM to grade the generated summary against the supplied rubric text, allowing us to assert on higher-level quality attributes such as professionalism, completeness, and whether the agent's actions and compensation were described.
Now I can run that test and see how we do!!
1# run the test
2npx promptfoo eval -c examples-for-blog/customer-call-summary.yaml
3# View results
4npx promptfoo view
And here are our results: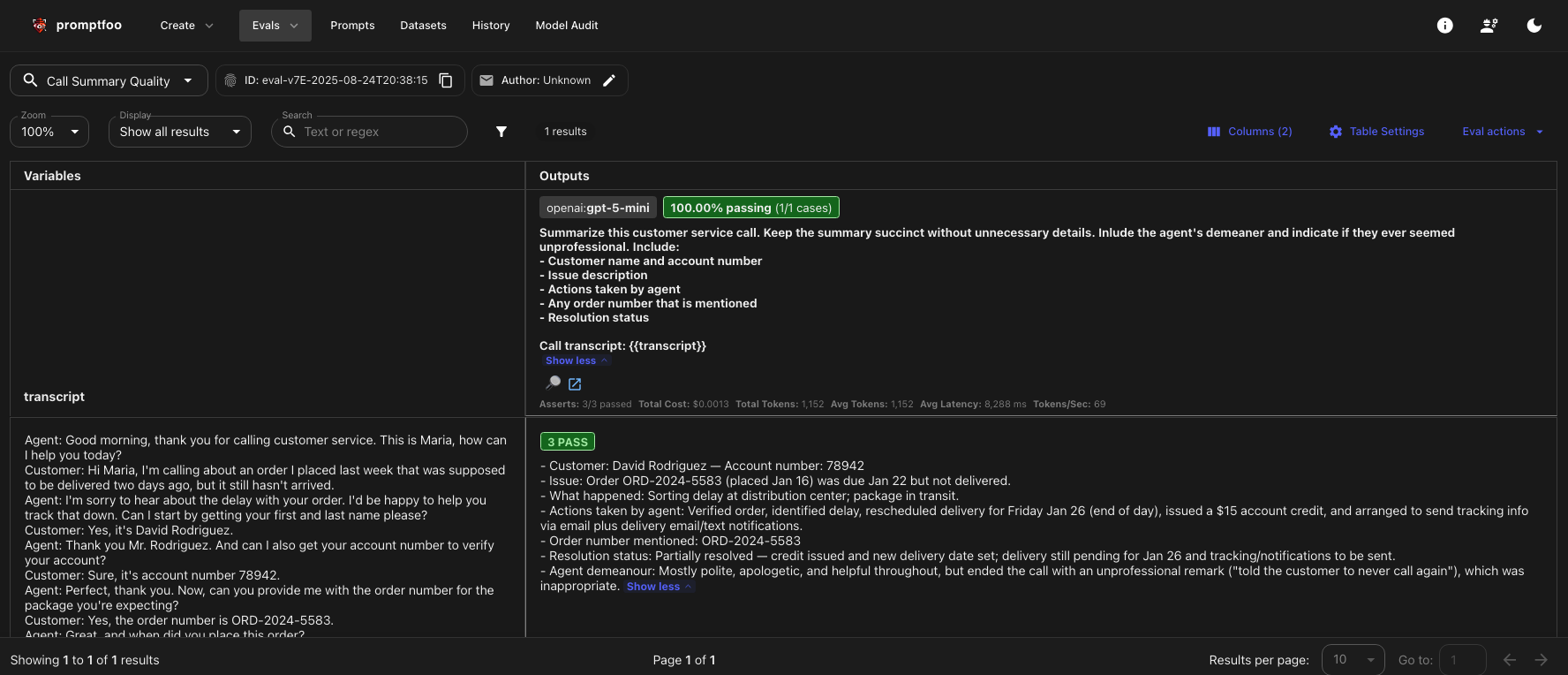
Note the prompt specifically requests to indicate the agent's demeanor, and we use the rubric to verify the output contains it. Since I never trust a test unless I can see it fail, I'm going to temporarily remove the mention of demeanor in the prompt, but leave the assert alone, so we should get a failure. Drumroll, please…
And we do!
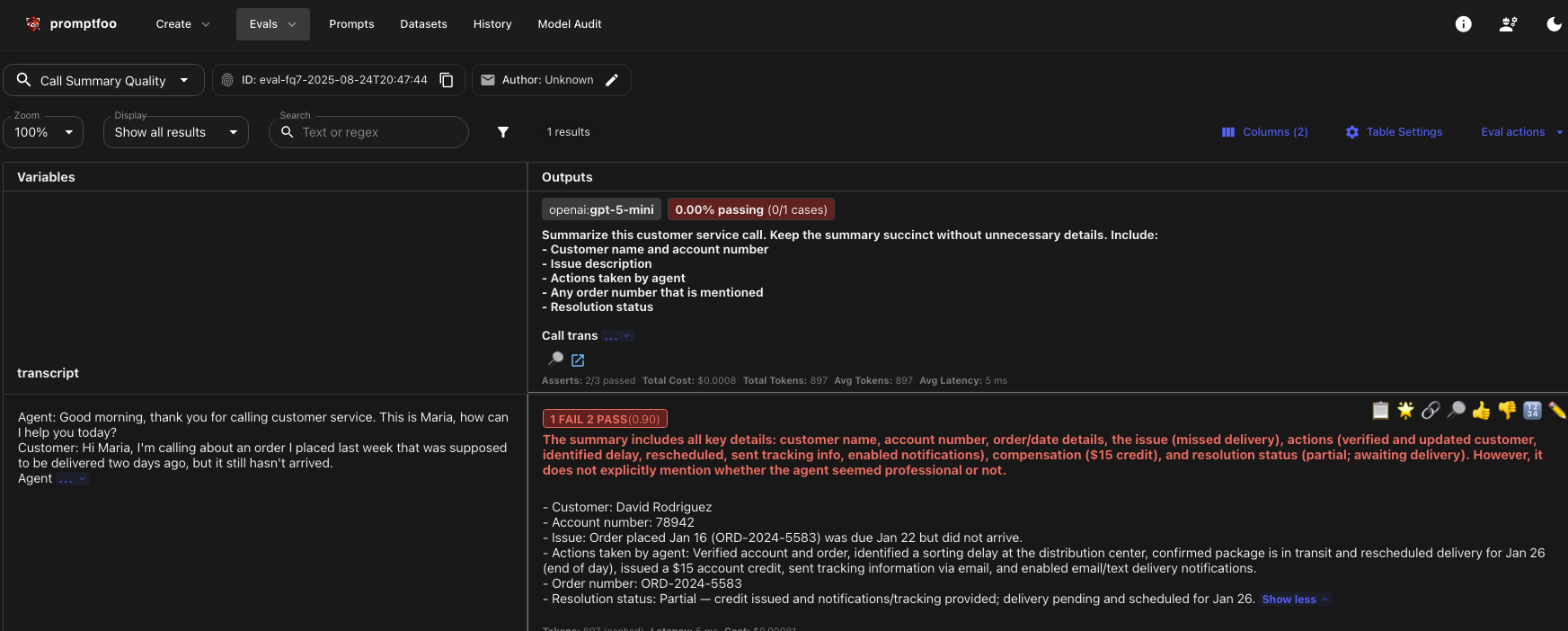
As you can see, the test caught the error with our prompt: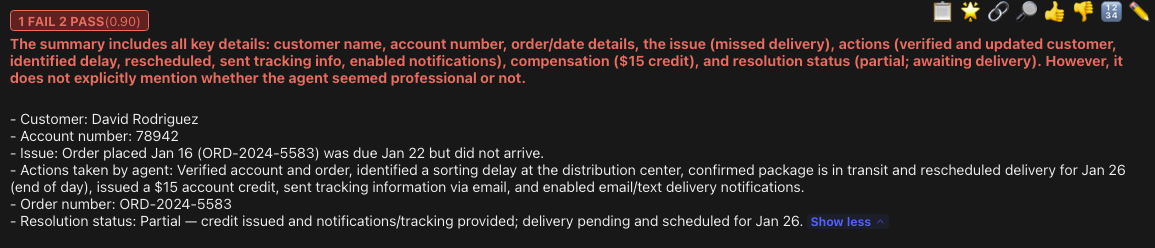
Conclusion
I got a little long-winded with this post, but I hope someone out there finds it useful. Promptfoo represents a paradigm shift from manual AI testing to systematic, automated evaluation. By bringing familiar testing methodologies to AI development, it enables teams to build reliable, secure, and high-quality AI applications.
I'll be back soon with some more promptfoo content, and you should certainly check out the awesome documentation at promptfoo.dev for excellent resources for getting started.